
Hi all,
When loading the mini dataset I use the following code:
‘’’
current_dir = os.getcwd()
dataroot = os.path.join(current_dir,“data”,“sets”,“nuscenes”,“mini”)
nusc = NuScenes(version=‘v1.0-mini’, dataroot=dataroot, verbose=True)
‘’’
and my mini folder looks like this:
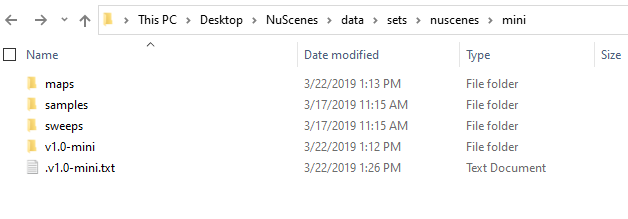
I have downloaded two parts of the trainval set, but I was a bit confused as to how to combine the parts and access the entire set. After extracting everything from the .tgz files my directory structure looks like
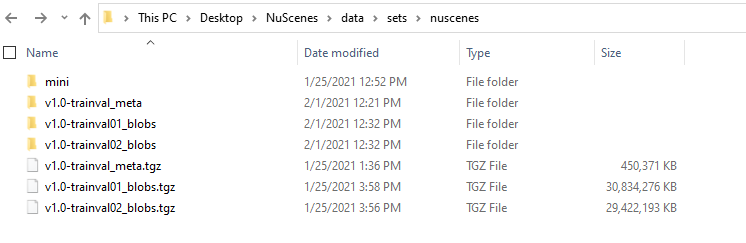
As you can see there are two separate folders containing trainval01 and trainval02 and I was unsure how to deal with this. Do I have to somehow consolidate all the data into one folder? Alternatively, do I simply set the dataroot to be the directory containing the trainval01 and trainval02 data? Or am I supposed to separately load each part of the data with multiple instantiations of the Nuscenes() class? Any clarification on how to go about this would be extremely helpful.